Benchmarking LLM training with the Liger Kernel#
Liger Kernel is a set of Triton kernels designed specifically for LLM training. It can increase GPU training throughput by up to 20% and reduces memory usage by up to 60%.
The official repo contains benchmark results for several larger models, like Llama3-8B, Qwen2-7B, and Gemma-7B, which shows the performance benefits of using the components of the Liger Kernel.
This tutorial demonstrates how to run a fine-tuning benchmarking experiment
using the Liger kernel on a smaller language model, Phi3 mini,
a 3.8B parameter model. We’ll use the alpaca
dataset and the HuggingFace transformers and trl libraries for training.
For evaluation metrics, we’ll compare token throughput and peak memory usage
between using the Liger kernel vs not using it.
We’ll scale down the experiment to train on a sequence length of 128 tokens so that each run trains on a single A100 GPU.
First, let’s import the necessary libraries:
Run on Union Serverless
Once you have a Union account, install union:
pip install union
Then run the following commands to run the workflow:
git clone https://github.com/unionai/unionai-examples
cd unionai-examples/tutorials/liger_kernel_finetuning
# create a huggingface key: https://huggingface.co/settings/tokens, then run the following command
union secrets create huggingface_api_key --value <your_huggingface_api_key>
# create a weights and biases key: https://wandb.ai/settings, then run the following command
union secrets create wandb_api_key --value <your_wandb_api_key>
union run --remote liger_kernel_finetuning.py benchmarking_experiment --inputs-file phi3_inputs.yaml
The source code for this tutorial can be found here .
import itertools
import json
import os
from copy import deepcopy
from dataclasses import dataclass, asdict, field
from functools import partial
from pathlib import Path
from typing import Optional
import pandas as pd
from flytekit import (
current_context,
dynamic,
map_task,
task,
workflow,
Deck,
ImageSpec,
Resources,
Secret,
)
from flytekit.extras.accelerators import A100
from flytekit.types.directory import FlyteDirectory
from flytekit.types.file import FlyteFile
from flytekitplugins.deck.renderer import TableRenderer, FrameProfilingRenderer
from flytekitplugins.wandb import wandb_init
import transformers
from callback import EfficiencyCallback
Define Python dependencies#
Then we’ll define the image specification for the container we’ll use to run the experiment.
image = ImageSpec(
name="liger-kernel-finetuning",
packages=[
"datasets==2.21.0",
"flytekitplugins-deck-standard",
"flytekitplugins-wandb",
"huggingface-hub==0.24.6",
"liger-kernel==0.2.1",
"matplotlib==3.9.2",
"pandas==2.2.2",
"seaborn==0.13.2",
"transformers==4.43.3",
"trl==0.10.1",
"torch==2.4.1",
],
apt_packages=["build-essential"],
cuda="12.1",
registry=os.environ.get("IMAGE_SPEC_REGISTRY"),
)
Define types and global variables#
We’ll define some global variables for the Weights and Biases project and entity so that we can track the experiment runs in the Weights and Biases UI.
We also define dataclasses for custom arguments, experiment arguments, training arguments, and training results, which we’ll use to analyze the experiment.
WANDB_PROJECT = "liger-kernel-finetuning" # replace this with your wandb project name
WANDB_ENTITY = "union-examples" # replace this with your wandb entity (username or team name)
@dataclass
class CustomArguments:
model_name: str = "microsoft/Phi-3-mini-4k-instruct"
dataset_name: str = "tatsu-lab/alpaca"
max_seq_length: int = 512
use_liger: bool = False
run_number: Optional[int] = None
@dataclass
class ExperimentArguments:
use_liger: list[bool] = field(default_factory=lambda: [True])
per_device_train_batch_size: list[int] = field(default_factory=lambda: [8])
@dataclass
class TrainingArguments(CustomArguments):
bf16: bool = True
max_steps: int = 10
num_train_epochs: int = 1
optim: str = "adamw_torch"
per_device_train_batch_size: int = 2
per_device_eval_batch_size: int = 2
eval_strategy: str = "no"
save_strategy: str = "no"
learning_rate: float = 0.000006
weight_decay: float = 0.05
warmup_ratio: float = 0.1
lr_scheduler_type: str = "cosine"
logging_steps: int = 1
include_num_input_tokens_seen: bool = True
report_to: str = "none"
seed: int = 42
fsdp: str = ""
fsdp_config: dict | None = field(default=None)
@dataclass
class TrainingResult:
model_dir: FlyteDirectory
training_history: FlyteFile
training_args: TrainingArguments
Load and cache the dataset and model#
We’ll download the Alpaca dataset and Phi3 mini model from the HuggingFace Hub,
where the latter step requires a HuggingFace API token. Note that we set cache=True
with a cache_version so that Flyte will cache the results and not have to re-download
the dataset and model from HuggingFace Hub on subsequent runs.
@task(
container_image=image,
cache=True,
cache_version="v1",
)
def download_dataset(dataset_name: str) -> FlyteDirectory:
from datasets import load_dataset
working_dir = Path(current_context().working_directory)
dataset_cache_dir = working_dir / "dataset_cache"
load_dataset(dataset_name, cache_dir=dataset_cache_dir)
return dataset_cache_dir
@task(
container_image=image,
cache=True,
cache_version="v1",
limits=Resources(mem="4Gi", cpu="2"),
secret_requests=[Secret(key="huggingface_api_key")],
)
def download_model(model_name: str) -> FlyteDirectory:
from huggingface_hub import login, snapshot_download
ctx = current_context()
working_dir = Path(ctx.working_directory)
model_cache_dir = working_dir / "model_cache"
login(token=ctx.secrets.get(key="huggingface_api_key"))
snapshot_download(model_name, local_dir=model_cache_dir)
return model_cache_dir
Model training task#
Next, we define the training task, which uses a single A100 GPU to train the model.
To track the experiment runs, we use Weights and Biases, which requires a secret.
Create a key at https://wandb.ai/settings, then run the following command to create the secret:
union secrets create wandb_api_key --value <your_wandb_api_key>
Then, we can specify the Secret in the @task decorator.
The train_model task below will use the SFTTrainer class from the trl library
to fine-tune the model using the Alpaca dataset. Depending on the training_args input,
it will use the Liger kernel or not.
WANDB_SECRET = Secret(key="wandb_api_key")
@task(
container_image=image,
limits=Resources(mem="24Gi", cpu="12", gpu="1"),
accelerator=A100,
cache=True,
cache_version="v11",
secret_requests=[WANDB_SECRET],
environment={"TOKENIZERS_PARALLELISM": "false"},
)
@wandb_init(project=WANDB_PROJECT, entity=WANDB_ENTITY, secret=WANDB_SECRET)
def train_model(
training_args: TrainingArguments,
dataset_cache_dir: FlyteDirectory,
model_cache_dir: FlyteDirectory,
) -> TrainingResult:
import torch
from datasets import load_dataset
from liger_kernel.transformers import AutoLigerKernelForCausalLM
from trl import DataCollatorForCompletionOnlyLM, SFTTrainer
model_cache_dir.download()
dataset_cache_dir.download()
ctx = current_context()
working_dir = Path(ctx.working_directory)
train_dir = working_dir / "models"
parser = transformers.HfArgumentParser((transformers.TrainingArguments, CustomArguments))
hf_training_args, custom_args = parser.parse_dict(
{"output_dir": train_dir, **asdict(training_args)}
)
tokenizer = transformers.AutoTokenizer.from_pretrained(
training_args.model_name,
padding_side="left",
truncation_side="left",
)
tokenizer.pad_token = tokenizer.eos_token
dataset = load_dataset(dataset_cache_dir.path)["train"].train_test_split(test_size=0.1)
train_dataset = dataset["train"]
eval_dataset = dataset["test"]
# need to provide the response_prompt with enough context for the tokenizer to encode
# the repsonse prompt ids correctly:
# https://huggingface.co/docs/trl/en/sft_trainer#using-tokenids-directly-for-responsetemplate
response_prompt = tokenizer.encode("\n### Response:", add_special_tokens=False)[2:]
collator = DataCollatorForCompletionOnlyLM(
tokenizer=tokenizer,
response_template=response_prompt,
pad_to_multiple_of=16,
)
if custom_args.use_liger:
model = AutoLigerKernelForCausalLM.from_pretrained(
model_cache_dir.path,
trust_remote_code=True,
use_cache=False,
torch_dtype=torch.bfloat16,
)
else:
model = transformers.AutoModelForCausalLM.from_pretrained(
model_cache_dir.path,
trust_remote_code=True,
use_cache=False,
torch_dtype=torch.bfloat16,
)
print(f"Model:\n{model}")
print(f"Training arguments:\n{hf_training_args}")
def formatting_prompts_func(example):
return example["text"]
trainer = SFTTrainer(
model=model,
args=hf_training_args,
data_collator=collator,
tokenizer=tokenizer,
max_seq_length=custom_args.max_seq_length,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
formatting_func=formatting_prompts_func,
callbacks=[EfficiencyCallback()],
)
trainer.train()
# save training history to a file
training_history_file = working_dir / "training_history.json"
with training_history_file.open("w") as f:
json.dump(trainer.state.log_history, f)
return TrainingResult(
FlyteDirectory(hf_training_args.output_dir),
FlyteFile(training_history_file),
training_args,
)
Preparing the grid search space for the experiment#
To run the different experiment configurations in parallel, we need to prepare
the grid search space for the experiment. We’ll use itertools.product to generate
the different combinations of the experiment arguments.
@task(
container_image=image,
cache=True,
cache_version="v1",
)
def prepare_experiment_args(
experiment_args: ExperimentArguments,
training_args: TrainingArguments,
n_runs: int,
) -> list[TrainingArguments]:
training_args_list = []
for run_number, use_liger, bs in itertools.product(
*[
range(1, n_runs + 1),
experiment_args.use_liger,
experiment_args.per_device_train_batch_size,
],
):
args = deepcopy(training_args)
args.use_liger = use_liger
args.per_device_train_batch_size = bs
args.run_number = run_number
training_args_list.append(args)
return training_args_list
Cache the parallelized experiment runs#
We’ll use the dynamic decorator to run the experiment runs in parallel.
The cache=True argument will cache the results of the experiment runs so that
we don’t have to re-run them if we run the experiment with the same configuration.
Inside the run_cached_training_benchmark dynamic workflow, we use the map_task
construct to run train_model in parallel. By setting min_success_ratio=0.1, we
can ensure that the map_task will succeed even if only 10% of its sub-tasks succeed.
We can also set the max_concurrency to control the number of concurrent tasks,
since we don’t want to request too many A100 GPUs at once.
@dynamic(
container_image=image,
cache=True,
cache_version="1",
)
def run_cached_training_benchmark(
training_args_list: list[TrainingArguments],
dataset_cache_dir: FlyteDirectory,
model_cache_dir: FlyteDirectory,
) -> list[Optional[TrainingResult]]:
results = map_task(
partial(
train_model,
dataset_cache_dir=dataset_cache_dir,
model_cache_dir=model_cache_dir,
),
min_success_ratio=0.1,
max_concurrency=4,
)(training_args=training_args_list)
return results
Analyzing the experiment results#
The last step of the experiment workflow is to analyze the results. We’ll use the
analyze_results task to create some plots of avg_tokens_per_second and
step_peak_memory_reserved_MB against the batch size, colored by Liger kernel usage.
We’ll use Flyte Decks to display the results directly in the Union UI once the experiment
is completed.
@task(
container_image=image,
enable_deck=True,
limits=Resources(mem="2Gi", cpu="2"),
)
def analyze_results(results: list[Optional[TrainingResult]]) -> pd.DataFrame:
import matplotlib.pyplot as plt
import seaborn as sns
history_columns = ["epoch", "step"]
metrics = [
"step_tokens_per_second",
"avg_tokens_per_second",
"step_peak_memory_allocated_MB",
"step_peak_memory_reserved_MB",
"total_peak_memory_allocated_MB",
"total_peak_memory_reserved_MB",
]
experiment_vars = [*ExperimentArguments.__dataclass_fields__]
dataframe = []
for result in results:
if result is None:
continue
result.training_history.download()
exp_vars = {k: getattr(result.training_args, k) for k in experiment_vars}
with open(result.training_history.path, "r") as f:
run_results = pd.read_json(f).assign(
run_number=result.training_args.run_number,
**exp_vars,
)
dataframe.append(run_results)
dataframe = pd.concat(dataframe)
analysis_columns = ["run_number", *history_columns, *experiment_vars, *metrics]
analysis_df = dataframe[analysis_columns].dropna().drop_duplicates()
# try converting experiment_vars to numeric types
for col in experiment_vars:
analysis_df[col] = pd.to_numeric(analysis_df[col], errors="ignore", downcast="integer")
grpby = analysis_df.groupby(experiment_vars + ["run_number"])
avg_tokens_per_second = (
grpby.step_tokens_per_second.mean().rename("avg_tokens_per_second").to_frame()
)
step_peak_memory_reserved_mb = grpby.step_peak_memory_reserved_MB.max().to_frame()
fig, ax = plt.subplots(2, 1, figsize=(12, 10))
sns.barplot(
x="per_device_train_batch_size",
y="avg_tokens_per_second",
hue="use_liger",
data=avg_tokens_per_second.reset_index(),
ax=ax[0],
)
sns.barplot(
x="per_device_train_batch_size",
y="step_peak_memory_reserved_MB",
hue="use_liger",
data=step_peak_memory_reserved_mb.reset_index(),
ax=ax[1],
)
sns.despine()
# define deck reports
benchmark_deck = Deck("Benchmarking Results")
benchmark_deck.append(_convert_fig_into_html(fig))
benchmark_raw_data = Deck("Benchmarking Raw Data")
benchmark_raw_data.append(TableRenderer().to_html(df=avg_tokens_per_second.reset_index()))
benchmark_raw_data.append(
TableRenderer().to_html(df=step_peak_memory_reserved_mb.reset_index())
)
benchmark_data_profile = Deck("Benchmarking Data Profile")
benchmark_data_profile.append(
FrameProfilingRenderer().to_html(
df=analysis_df.assign(use_liger_int=lambda df: df["use_liger"].astype(int))
)
)
ctx = current_context()
ctx.decks.insert(0, benchmark_raw_data)
ctx.decks.insert(0, benchmark_data_profile)
ctx.decks.insert(0, benchmark_deck)
return analysis_df
LLM benchmarking workflow#
We put together all of the steps of the experiment pipeline together into a single
benchmarking_experiment workflow:
@workflow
def benchmarking_experiment(
experiment_args: ExperimentArguments = ExperimentArguments(),
training_args: TrainingArguments = TrainingArguments(),
n_runs: int = 3,
) -> tuple[list[Optional[TrainingResult]], pd.DataFrame]:
dataset_cache_dir = download_dataset(training_args.dataset_name)
model_cache_dir = download_model(training_args.model_name)
training_args_list = prepare_experiment_args(experiment_args, training_args, n_runs)
results = run_cached_training_benchmark(
training_args_list, dataset_cache_dir, model_cache_dir
)
analysis = analyze_results(results=results)
return results, analysis
Run the workflow using union run:
union run --remote --copy-all liger_kernel_finetuning.py benchmarking_experiment --inputs-file phi3_inputs.yaml
The inputs-file argument allows us to pass the TrainingArguments as a YAML file.
This will produce an execution graph that looks like the following:
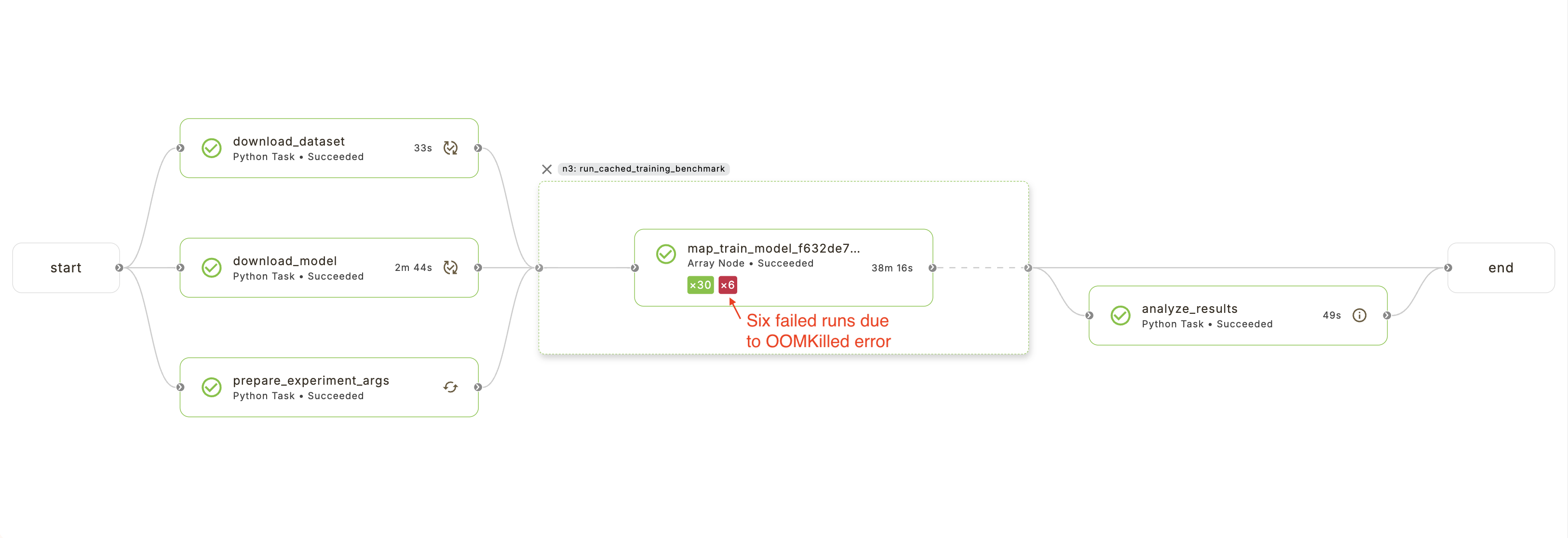
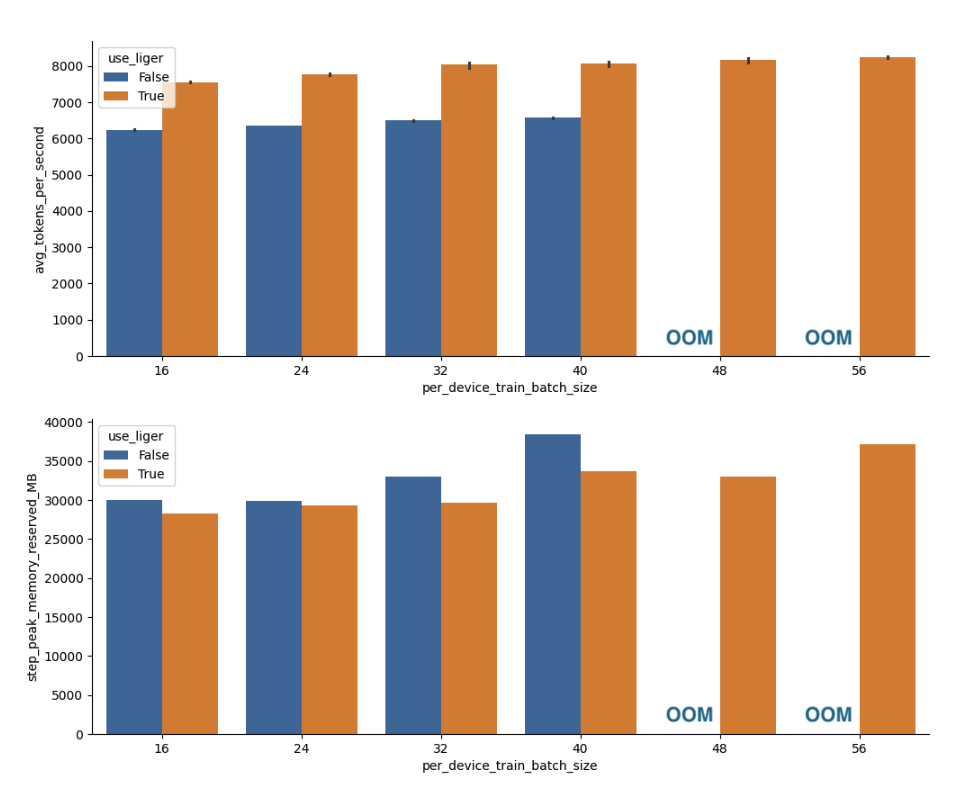
Results#
As we can see from the results, using the Liger kernel consistently improves the
token throughput and reduces the peak memory usage across the different batch sizes.
At batch sizes of 48 and 56, the vanilla transformers implementation of the Phi3 mini
model will error out with an out-of-memory error, while the Liger kernel implementation
can still train the model successfully.
Appendix#
Below is a helper funtion to convert a matplotlib figure into an HTML string,
which is used by the Flyte Deck to display the figures in the Union UI.
def _convert_fig_into_html(fig) -> str:
import io
import base64
import matplotlib as mpl
img_buf = io.BytesIO()
fig.savefig(img_buf, format="png")
img_base64 = base64.b64encode(img_buf.getvalue()).decode()
return f'<img src="data:image/png;base64,{img_base64}" alt="Rendered Image" />'