Serve vLLM on Union Actors for Named Entity Recognition#
This tutorial demonstrates how to deploy an automated, low-latency, named entity recognition workflow. Given some unstructured text, this workflow will locate and classify named entities using an LLM. In order to minimize latency, we will use Union actors which allow for container and environment reuse between tasks that need to maintain state. To further maximize inference efficiency, we will serve a Hugging Face model on our actor using vLLM. vLLM achieves state-of-the-art throughput with dynamic batching and caching mechanisms that maximize GPU utilization and reduces redundant computations.
Run on Union BYOC
Once you have a Union account, install union:
pip install union
Export the following environment variable to build and push images to your own container registry:
# replace with your registry name
export IMAGE_SPEC_REGISTRY="<your-container-registry>"
Then run the following commands to run the workflow:
git clone https://github.com/unionai/unionai-examples
cd unionai-examples/tutorials/vllm_serving_on_actor
union run --remote upstream.py upstream_wf
# follow the example below to create secrets before running this command
union run --remote ner.py ner_wf
The source code for this tutorial can be found here .
Creating Secrets to Pull Hugging Face Models#
In this example we will use the google/gemma-7b-it as it was fine-tuned on instruction-following datasets,
allowing it to handle conversational contexts. For our workflow to download the google/gemma-7b-it model,
we need to sign in to Hugging Face, accept the license for google/gemma-7b-it, and then generate an access token.
Then, we securely store our access token using the union CLI tool:
union create secret HF_TOKEN
and paste the access token when prompted.
With our Hugging Face credentials set up and saved on Union, we can import our dependencies and set some constants that we will use for our vLLM server and for saving the results:
import os
from textwrap import dedent
from typing import Tuple, List
from flytekit import ImageSpec, workflow, Secret, PodTemplate, kwtypes
from flytekit.extras.accelerators import A10G
from flytekitplugins.awssagemaker_inference import BotoConfig, BotoTask
from kubernetes.client import V1Toleration
from kubernetes.client.models import (
V1Container,
V1ContainerPort,
V1HTTPGetAction,
V1PodSpec,
V1Probe,
V1ResourceRequirements,
)
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
from union.actor import ActorEnvironment
from utils import TextSample, TextSampleArtifact
# Define a port and s3 locations
PORT = 8000
S3_BUCKET = "union-db-demo"
S3_DIRECTORY = "/"
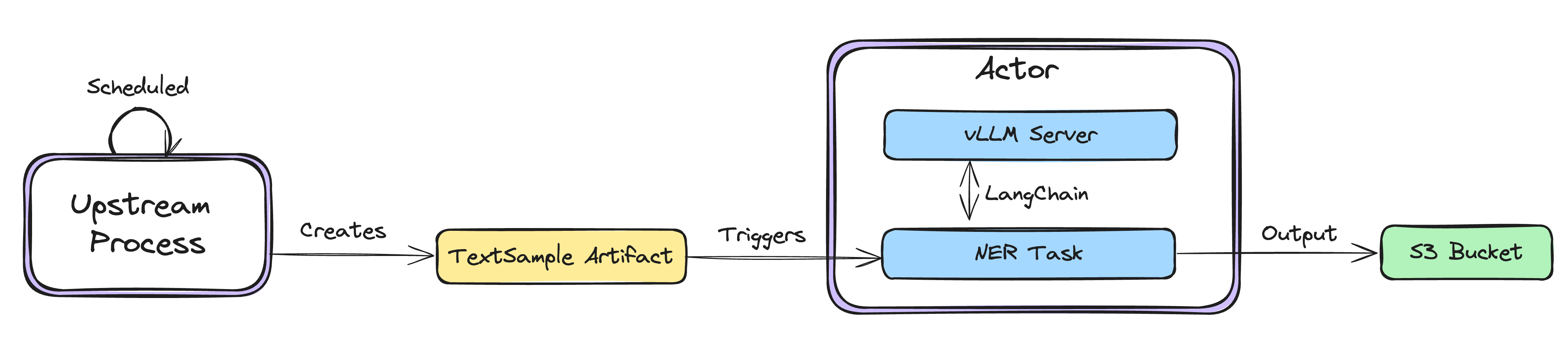
Upstream Workflow that Outputs Text#
Before we get to our vLLM server, we will mock up some upstream process that creates our text we want to perform
NER over. For the sake of example, we will randomly select a sentence from a small set of text samples. Our
workflow will run on a schedule and return a TextSample dataclass that is annotated with a TextSampleArtifact
Union artifact. By using Union artifacts, we can have Union automatically trigger our downstream vLLM inference
workflow automatically while maintaining data lineage between workflows.
from dataclasses import dataclass
from flytekit import Artifact
@dataclass
class TextSample:
id: str
body: str
TextSampleArtifact = Artifact(name="text_sample")
import random
from typing import Annotated
from flytekit import task, workflow
from utils import TextSample, TextSampleArtifact
@task
def get_text() -> TextSample:
text_samples = {
"1": "Elon Musk, the CEO of Tesla, announced a partnership with SpaceX to launch satellites from Cape Canaveral in 2024.",
"2": "On September 15th, 2023, Serena Williams won the U.S. Open at Arthur Ashe Stadium in New York City.",
"3": "President Joe Biden met with leaders from NATO in Brussels to discuss the conflict in Ukraine on July 10th, 2022.",
"4": "Sundar Pichai, the CEO of Google, gave the keynote speech at the Google I/O conference held in Mountain View on May 11th, 2023.",
"5": "J.K. Rowling, author of the Harry Potter series, gave a talk at Oxford University in December 2019.",
}
id = random.choice(list(text_samples.keys()))
return TextSample(id=id, body=text_samples[id])
@workflow
def upstream_wf() -> Annotated[TextSample, TextSampleArtifact]:
return get_text()
Separately, we can define launch plans that will run our upstream workflow on a schedule and automatically run our
downstream ner_wf upon the creation of a TextSampleArtifact artifact.
from datetime import timedelta from flytekit import LaunchPlan, FixedRate from
union.artifacts import OnArtifact
from ner import TextSampleArtifact, ner_wf, upstream_wf
upstream_lp = LaunchPlan.get_or_create(
workflow=upstream_wf, name="upstream_lp", schedule=FixedRate(duration=timedelta(minutes=1))
)
ner_lp = LaunchPlan.get_or_create(
workflow=ner_wf, name="ner_lp_v4", trigger=OnArtifact(trigger_on=TextSampleArtifact)
)
Now, let’s look into how we can create our downstream ner_wf workflow for named entity recognition.
Defining a Container Image#
To allow our remote vLLM server to use all the dependencies we previously imported, we need to define a container
image. Rather than writing a Dockerfile, we can define our dependencies within an ImageSpec. This ImageSpec
installs all our packages ontop of a base image that already contains the latest version of flytekit. We also
include the build-essential APT package which is necessary for vllm.
image = ImageSpec(
registry=os.environ.get("IMAGE_SPEC_REGISTRY"),
packages=[
"vllm==0.6.2",
"union==0.1.82",
"kubernetes==31.0.0",
"flytekitplugins-awssagemaker==1.13.8",
"langchain==0.3.3",
"langchain-openai==0.2.2",
],
apt_packages=["build-essential"],
)
Actor Deployment#
There are multiple ways we can run an external server on a Flyte task, however in this example we will use an init container within a Kubernetes pod. Init containers are specialized containers that run before the main application containers in a Pod. They are used to perform setup or initialization tasks that need to be completed before the main containers start. We will have our actor environment handle creating the primary container which will handle calling the vLLM server. This container will that will sit beside our init container in a pod on our cluster.
For Kubernetes-level configuration like this, we can use PodTemplates. In this PodTemplate we expose port 8000
for communication between our init container and primary container. We can also add tolerations and a
node_selector in order to target a L4 GPU. Finally, we add a command which loads our Hugging Face token as en
environment variable and starts serving a google/gemma-7b-it model.
start_vllm_server = """\
from flytekit import current_context;\
import os;\
import subprocess;\
os.environ['HF_TOKEN'] = current_context().secrets.get(key='HF_TOKEN');\
subprocess.run([\
'python', '-m', 'vllm.entrypoints.openai.api_server',\
'--model=google/gemma-7b-it',\
'--dtype=half',\
'--max-model-len=2000'\
])\
"""
pod_template = PodTemplate(
pod_spec=V1PodSpec(
containers=[],
init_containers=[
V1Container(
name="vllm",
image=image.image_name(),
ports=[V1ContainerPort(container_port=PORT)],
resources=V1ResourceRequirements(
requests={
"cpu": "2",
"memory": "10Gi",
"nvidia.com/gpu": "1",
},
limits={
"cpu": "2",
"memory": "10Gi",
"nvidia.com/gpu": "1",
},
),
command=[
"python",
"-c",
start_vllm_server,
],
restart_policy="Always",
startup_probe=V1Probe(
http_get=V1HTTPGetAction(port=PORT, path="/health"),
failure_threshold=100,
),
),
],
node_selector={"k8s.amazonaws.com/accelerator": "nvidia-tesla-l4"},
tolerations=[
V1Toleration(
effect="NoSchedule",
key="k8s.amazonaws.com/accelerator",
operator="Equal",
value="nvidia-l4",
),
V1Toleration(
effect="NoSchedule",
key="nvidia.com/gpu",
operator="Equal",
value="present",
),
],
),
)
Notice the inclusion of secret_requests in the ActorEnvironment which allows us to target our Hugging Face
token in the PodTemplate command. For this example we will just use one actor replica, which means all requests
will go through the same vLLM server, however more replicas can be created if desired. We will also set a “time to
live” of 5-minutes using ttl_seconds which controls how long the actor stays alive after the last task it processes.
actor_env = ActorEnvironment(
name="vllm-actor",
replica_count=1,
pod_template=pod_template,
container_image=image,
ttl_seconds=300,
secret_requests=[Secret(key="HF_TOKEN")],
)
Named Entity Recognition Task#
This is where the core logic of our workflow takes place. We set some environment variables directing langchain
to our vLLM server, define the output format using pydantic, and insert our text into a named entity recognition
prompt. The output of this task is a json string containing the named entities in the text, and the location for
which the string should be saved.
@actor_env.task
def ner(text: TextSample) -> Tuple[str, str]:
# Set up the environment for the local vLLM server
os.environ["OPENAI_API_KEY"] = "EMPTY" # vLLM doesn't require an API key
os.environ["OPENAI_API_BASE"] = (
f"http://0.0.0.0:{PORT}/v1" # Update with your vLLM server address
)
# Define the Pydantic model for structured output
class EntityExtraction(BaseModel):
persons: List[str] = Field(description="List of person names")
organizations: List[str] = Field(description="List of organization names")
locations: List[str] = Field(description="List of location names")
dates: List[str] = Field(description="List of dates")
# Create a ChatOpenAI instance configured to use the local vLLM server
model = ChatOpenAI(model="google/gemma-7b-it", temperature=0)
# Create a model with structured output
ner_model = model.with_structured_output(EntityExtraction)
prompt = f"""
Extract all named entities such as persons, organizations, locations, and dates from the following text:
{text.body}
Provide your response as a structured output matching the EntityExtraction schema.
"""
response = ner_model.invoke([HumanMessage(content=dedent(prompt))])
return f"{S3_DIRECTORY}/{text.id}/named_entities.json", response.json()
Saving the NER Result#
We can efficiently save the results to S3 using the Boto agent which is part of the AWS Sagemaker integration and
can invoke any boto3 method.
put_object_config = BotoConfig(
service="s3",
method="put_object",
config={
"Bucket": "{inputs.bucket}",
"Key": "{inputs.key}",
"Body": "{inputs.body}",
},
images={"primary_container_image": image},
region="us-east-2",
)
put_object_task = BotoTask(
name="put_object",
task_config=put_object_config,
inputs=kwtypes(bucket=str, key=str, body=str),
)
Constructing the Final Workflow#
Finally, we reach the ner_wf which we originally referenced in the aforementioned ner_lp. Here we query for the
TextSampleArtifact artifact created by our upstream process, pass the TextSample to our NER actor, and push the
result to S3 so it is available to other applications in our stack.
@workflow
def ner_wf(text: TextSample = TextSampleArtifact.query()):
file_name, named_entities = ner(text=text)
put_object_task(bucket=S3_BUCKET, key=file_name, body=named_entities)
To register and activate this LaunchPlan we run:
union register tutorials/vllm_serving_on_actor/
union launchplan ner_lp --activate
union launchplan upstream_lp --activate
The upstream workflow will run on its configured scedule, triggering the NEW workflow until the launch plans are deactivated either in the UI or using:
union launchplan ner_lp --deactivate
union launchplan upstream_lp --deactivate