Caching#
Union.ai allows you to cache the output of nodes (tasks, subworkflows, and sub-launch plans) to make subsequent executions faster.
Caching is useful when many executions of identical code with the same input may occur.
Here’s a video with a brief explanation and demo, focused on task caching:
Note
Caching is available and individiually enablable for all nodes within a workflow directed acyclic graph (DAG).
Nodes in this sense include tasks, subworkflows (workflows called directly within another workflow), and sub-launch plans (launch plans called within a workflow).
Caching is not available for top-level workflows or launch plans (that is, those invoked from UI or CLI).
By default, caching is disabled on all tasks, subworkflows and sub-launch plans, to avoid unintended consequences when caching executions with side effects. It must be explcitly enabled on any node where caching is desired.
Enabling and configuring caching#
Caching can be enabled by setting the cache parameter of the @union.task (for tasks) decorator or with_overrides method (for subworkflows or sub-launch plans) to a Cache object. The parameters of the Cache object are used to configure the caching behavior.
For example:
import union
# Define a task and enable caching for it
@union.task(cache=union.Cache(version="1.0", serialize=True, ignored_inputs=["a"]))
def sum(a: int, b: int, c: int) -> int:
return a + b + c
# Define a workflow to be used as a subworkflow
@union.workflow
def child_wf(a: int, b: int, c: int) -> list[int]:
return [
sum(a=a, b=b, c=c)
for _ in range(5)
]
# Define a launch plan to be used as a sub-launch plan
child_lp = union.LaunchPlan.get_or_create(child_wf)
# Define a parent workflow that uses the subworkflow
@union.workflow
def parent_wf_with_subwf(input: int = 0):
return [
# Enable caching on the subworkflow
child_wf(a=input, b=3, c=4).with_overrides(cache=union.Cache(version="1.0", serialize=True, ignored_inputs=["a"]))
for i in [1, 2, 3]
]
# Define a parent workflow that uses the sub-launch plan
@union.workflow
def parent_wf_with_sublp(input: int = 0):
return [
child_lp(a=input, b=1, c=2).with_overrides(cache=union.Cache(version="1.0", serialize=True, ignored_inputs=["a"]))
for i in [1, 2, 3]
]
In the above example, caching is enabled at multiple levels:
At the task level, in the
@union.taskdecorator of the tasksum.At the workflow level, in the
with_overridesmethod of the invocation of the workflowchild_wf.At the launch plan level, in the
with_overridesmethod of the invocation of the launch planchild_lp.
In each case, the result of the execution is cached and reused in subsequent executions.
Here the reuse is demonstrated by calling the child_wf and child_lp workflows multiple times with the same inputs.
Additionally, if the same node is invoked again with the same inputs (excluding input “a”, as it is ignored for purposes of versioning)
the cached result is returned immediately instead of re-executing the process.
This applies even if the cached node is invoked externally through the UI or CLI.
The Cache object#
The Cache object takes the following parameters:
version(Optional[str]): Part of the cache key. A change to this parameter from one invocation to the next will invalidate the cache. This allows you to explicitly indicate when a change has been made to the node that should invalidate any existing cached results. Note that this is not the only change that will invalidate the cache (see below). Also, note that you can manually trigger cache invalidation per execution using theoverwrite-cacheflag. If not set, the version will be generated based on the specified cache policies. When usingcache=True, as shown below, the default cache policy generates the version.serialize(bool): Enables or disables cache serialization. When enabled, Union.ai ensures that a single instance of the node is run before any other instances that would otherwise run concurrently. This allows the initial instance to cache its result and lets the later instances reuse the resulting cached outputs. If not set, cache serialization is disabled.ignored_inputs(Union.ai[Tuple[str, ...], str]): Input variables that should not be included when calculating the hash for the cache. If not set, no inputs are ignored.policies(Optional[Union.ai[List[CachePolicy], CachePolicy]]): A list of CachePolicy objects used for automatic version generation. If noversionis specified and one or more polices are specified then these policies automatically generate the version. Policies are applied in the order they are specified to produce the finalversion. If noversionis specified and no policies are specified then the default cache policy generates the version. When usingcache=True, as shown below, the default cache policy generates the version.salt(str): A salt used in the hash generation. A salt is a random value that is combined with the input values before hashing.
Enabling caching with the default configuration#
Instead of specifying a Cache object, a simpler way to enable caching is to set cache=True in the @union.task decorator (for tasks) or the with_overrides method (for subworkflows and sub-launch plans).
When cache=True is set, caching is enabled with the following configuration:
versionis automatically generated by the default cache policy.serializeis set toFalse.ignored_inputsis not set. No parameters are ignored.
You can convert the example above to use the default configuration throughout by changing each instance of cache=union.Cache(...) to cache=True. For example, the task sum would now be:
@union.task(cache=True)
def sum(a: int, b: int, c: int) -> int:
return a + b + c
Automatic version generation#
Automatic version generation is useful when you want to generate the version based on the function body of the task, or other criteria.
You can enable automatic version generation by specifying cache=Cache(...) with one or more CachePolicy classes in the policies parameter of the Cache object (and by not specifying an explicit version parameter), like this:
@union.task(cache=Cache(policies=[CacheFunctionBody()]))
def sum(a: int, b: int, c: int) -> int:
return a + b + c
Alternatively, you can just use the default configuration by specify use cache=True. In this case the default cache policy is used to generate the version.
Default cache policy#
Automatic version generation using the default cache policy is used
if you set
cache=True, orif you set
cache=Cache(...)but do not specify an explicitversionorpoliciesparameters within theCacheobject.
The default cache policy is union.cache.CacheFunctionBody.
This policy generates a version by hashing the text of the function body of the task.
This means that if the code in the function body changes, the version changes, and the cache is invalidated. Note that CacheFunctionBody does not recursively check for changes in functions or classes referenced in the function body.
The overwrite-cache flag#
When launching the execution of a workflow, launch plan or task, you can use the overwrite-cache flag to invalidate the cache and force re-execution.
Overwrite cache on the command line#
The overwrite-cache flag can be used from the command line with the union run command. For example:
$ union run --remote --overwrite-cache example.py wf
Overwrite cache in the UI#
You can also trigger cache invalidation when launching an execution from the UI by checking the **Override, in the launch dialog:
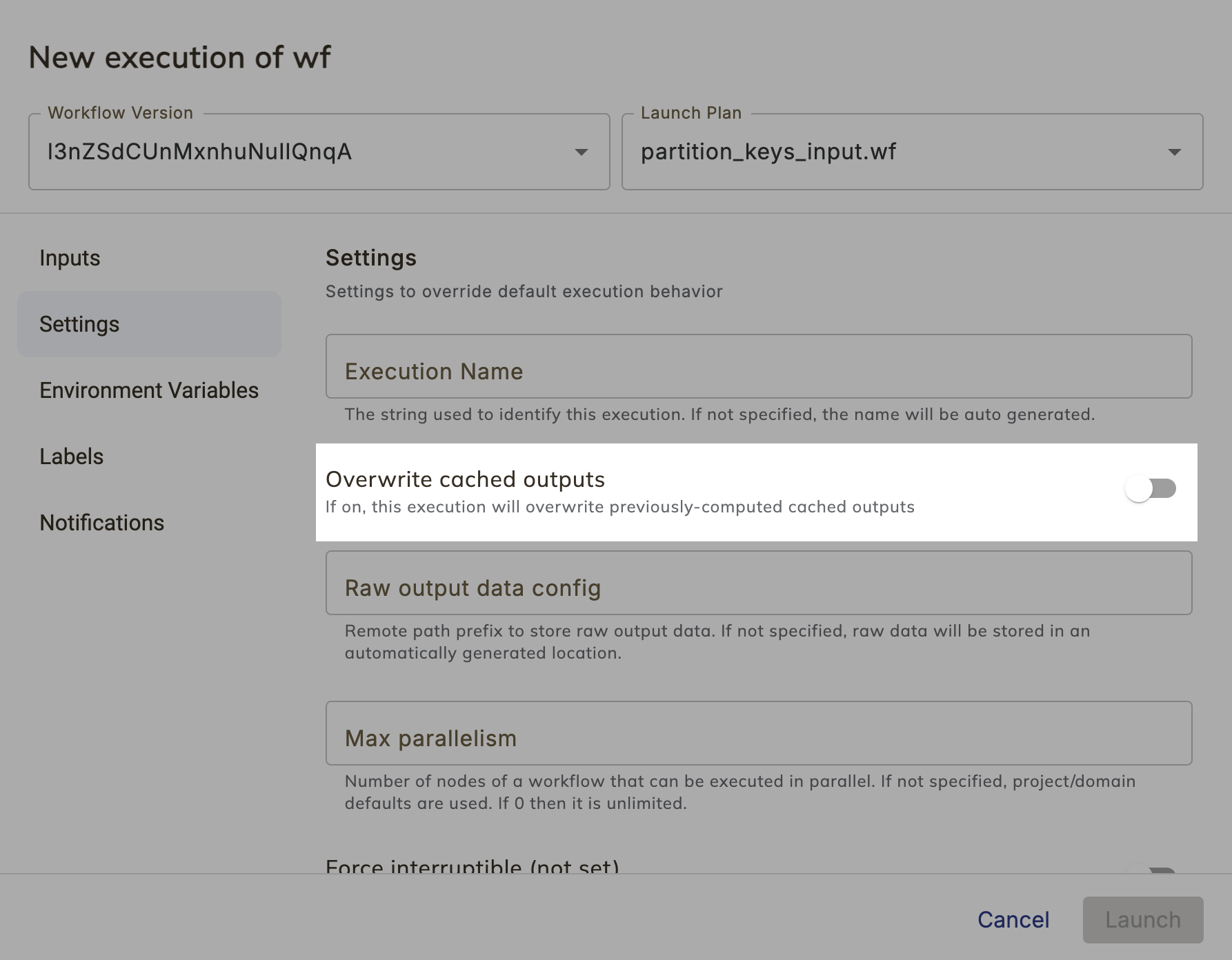
Overwrite cache programmatically#
When using UnionRemote, you can use the overwrite_cache parameter in the flytekit.remote.remote.FlyteRemote.execute method:
from union.remote import UnionRemote
remote = UnionRemote()
wf = remote.fetch_workflow(name="workflows.example.wf")
execution = remote.execute(wf, inputs={"name": "Kermit"}, overwrite_cache=True)
How caching works#
When a node (with caching enabled) completes on Union.ai, a key-value entry is created in the caching table. The value of the entry is the output. The key is composed of:
Project: A task run under one project cannot use the cached task execution from another project which would cause inadvertent results between project teams that could result in data corruption.
Domain: To separate test, staging, and production data, task executions are not shared across these environments.
Cache Version: The cache version is either explicitly set using the
versionparameter in theCacheobject or automatically set by a cache policy (see Automatic version generation). If the version changes (either explicitly or automatically), the cache entry is invalidated.Node signature: The cache is specific to the signature associated with the execution. The signature comprises the name, input parameter names/types, and the output parameter name/type of the node. If the signature changes, the cache entry is invalidated.
Input values: A well-formed Union.ai node always produces deterministic outputs. This means that, given a set of input values, every execution should have identical outputs. When an execution is cached, the input values are part of the cache key. If a node is run with a new set of inputs, a new cache entry is created for the combination of that particular entity with those particular inputs.
The result is that within a given project and domain, a cache entry is created for each distinct combination of name, signature, cache version, and input set for every node that has caching enabled. If the same node with the same input values is encountered again, the cached output is used instead of running the process again.
Explicit cache version#
When a change to code is made that should invalidate the cache for that node, you can explicitly indicate this by incrementing the version parameter value.
For a task example, see below. (For workflows and launch plans, the parameter would be specified in the with_overrides method.)
@union.task(cache=union.Cache(version="1.1"))
def t(n: int) -> int:
return n * n + 1
Here the version parameter has been bumped from 1.0to 1.1, invalidating of the existing cache.
The next time the task is called it will be executed and the result re-cached under an updated key.
However, if you change the version back to 1.0, you will get a “cache hit” again and skip the execution of the task code.
If used, the version parameter must be explicitly changed in order to invalidate the cache.
(if not used, then a cache policy may be specified to generate the version, or you can rely on the default cache policy).
Not every Git revision of a node will necessarily invalidate the cache.
A change in Git SHA does not necessarily correlate to a change in functionality.
You can refine your code without invalidating the cache as long as you explicitly use, and don’t change, the version parameter (or the signature, see below) of the node.
The idea behind this is to decouple syntactic sugar (for example, changed documentation or renamed variables) from changes to logic that can affect the process’s result. When you use Git (or any version control system), you have a new version per code change. Since the behavior of most nodes in a Git repository will remain unchanged, you don’t want their cached outputs to be lost.
When a node’s behavior does change though, you can bump version to invalidate the cache entry and make the system recompute the outputs.
Node signature#
If you modify the signature of a node by adding, removing, or editing input parameters or output return types, Union.ai invalidates the cache entries for that node. During the next execution, Union.ai executes the process again and caches the outputs as new values stored under an updated key.
Cache serialization#
Cache serialization means only executing a single instance of a unique cacheable task (determined by the cache_version parameter and task signature) at a time.
Using this mechanism, Flyte ensures that during multiple concurrent executions of a task only a single instance is evaluated, and all others wait until completion and reuse the resulting cached outputs.
Ensuring serialized evaluation requires a small degree of overhead to coordinate executions using a lightweight artifact reservation system. Therefore, this should be viewed as an extension to rather than a replacement for non-serialized cacheable tasks. It is particularly well fit for long-running or otherwise computationally expensive tasks executed in scenarios similar to the following examples:
Periodically scheduled workflow where a single task evaluation duration may span multiple scheduled executions.
Running a commonly shared task within different workflows (which receive the same inputs).
Enabling cache serialization#
Task cache serializing is disabled by default to avoid unexpected behavior for task executions.
To enable, set serialize=True in the @union.task decorator.
The cache key definitions follow the same rules as non-serialized cache tasks.
@union.task(cache=union.Cache(version="1.1", serialize=True))
def t(n: int) -> int:
return n * n
In the above example calling t(n=2) multiple times concurrently (even in different executions or workflows) will only execute the multiplication operation once.
Concurrently evaluated tasks will wait for completion of the first instance before reusing the cached results and subsequent evaluations will instantly reuse existing cache results.
How does cache serialization work?#
The cache serialization paradigm introduces a new artifact reservation system. Executions with cache serialization enabled use this reservation system to acquire an artifact reservation, indicating that they are actively evaluating a node, and release the reservation once the execution is completed. Union.ai uses a clock-skew algorithm to define reservation timeouts. Therefore, executions are required to periodically extend the reservation during their run.
The first execution of a serializable node will successfully acquire the artifact reservation. Execution will be performed as usual and upon completion, the results are written to the cache, and the reservation is released. Concurrently executed node instances (those that would otherwise run in parallel with the initial execution) will observe an active reservation, in which case these instances will wait until the next reevaluation and perform another check. Once the initial execution completes, they will reuse the cached results as will any subsequent instances of the same node.
Union.ai handles execution failures using a timeout on the reservation. If the execution currently holding the reservation fails to extend it before it times out, another execution may acquire the reservation and begin processing.
Caching of offloaded objects#
In some cases, the default behavior displayed by Union.ai’s caching feature might not match the user’s intuition. For example, this code makes use of pandas dataframes:
@union.task
def foo(a: int, b: str) -> pandas.DataFrame:
df = pandas.DataFrame(...)
...
return df
@union.task(cache=True)
def bar(df: pandas.DataFrame) -> int:
...
@union.workflow
def wf(a: int, b: str):
df = foo(a=a, b=b)
v = bar(df=df)
If run twice with the same inputs, one would expect that bar would trigger a cache hit, but that’s not the case because of the way dataframes are represented in Union.ai.
However, Union.ai provides a new way to control the caching behavior of literals.
This is done via a typing.Annotated call on the node signature.
For example, in order to cache the result of calls to bar, you can rewrite the code above like this:
def hash_pandas_dataframe(df: pandas.DataFrame) -> str:
return str(pandas.util.hash_pandas_object(df))
@union.task
def foo_1(a: int, b: str) -> Annotated[pandas.DataFrame, HashMethod(hash_pandas_dataframe)]:
df = pandas.DataFrame(...)
...
return df
@union.task(cache=True)
def bar_1(df: pandas.DataFrame) -> int:
...
@union.workflow
def wf_1(a: int, b: str):
df = foo(a=a, b=b)
v = bar(df=df)
Note how the output of the task foo is annotated with an object of type HashMethod.
Essentially, it represents a function that produces a hash that is used as part of the cache key calculation in calling the task bar.
How does caching of offloaded objects work?#
Recall how input values are taken into account to derive a cache key.
This is done by turning the literal representation into a string and using that string as part of the cache key.
In the case of dataframes annotated with HashMethod, we use the hash as the representation of the literal.
In other words, the literal hash is used in the cache key.
This feature also works in local execution.
Here’s a complete example of the feature:
def hash_pandas_dataframe(df: pandas.DataFrame) -> str:
return str(pandas.util.hash_pandas_object(df))
@union.task
def uncached_data_reading_task() -> Annotated[pandas.DataFrame, HashMethod(hash_pandas_dataframe)]:
return pandas.DataFrame({"column_1": [1, 2, 3]})
@union.task(cache=True)
def cached_data_processing_task(df: pandas.DataFrame) -> pandas.DataFrame:
time.sleep(1)
return df * 2
@union.task
def compare_dataframes(df1: pandas.DataFrame, df2: pandas.DataFrame):
assert df1.equals(df2)
@union.workflow
def cached_dataframe_wf():
raw_data = uncached_data_reading_task()
# Execute `cached_data_processing_task` twice, but force those
# two executions to happen serially to demonstrate how the second run
# hits the cache.
t1_node = create_node(cached_data_processing_task, df=raw_data)
t2_node = create_node(cached_data_processing_task, df=raw_data)
t1_node >> t2_node
# Confirm that the dataframes actually match
compare_dataframes(df1=t1_node.o0, df2=t2_node.o0)
if __name__ == "__main__":
df1 = cached_dataframe_wf()
print(f"Running cached_dataframe_wf once : {df1}")